用Jsoup造最简单的网页爬虫
本文介绍利用jsoup写的简易网页爬虫,爬自己的Blog作为测试。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
准备工作:
1.Intellij等建好项目
2.到http://jsoup.org/packages/jsoup-1.8.3.jar下载好jsoup包
3.将包导入到项目library中即可
关键
1.使用Chorome审查元素浏览页面,分析所需要抓取的位置。 2.使用选择器语法,能够正确得到Elements和element对象。
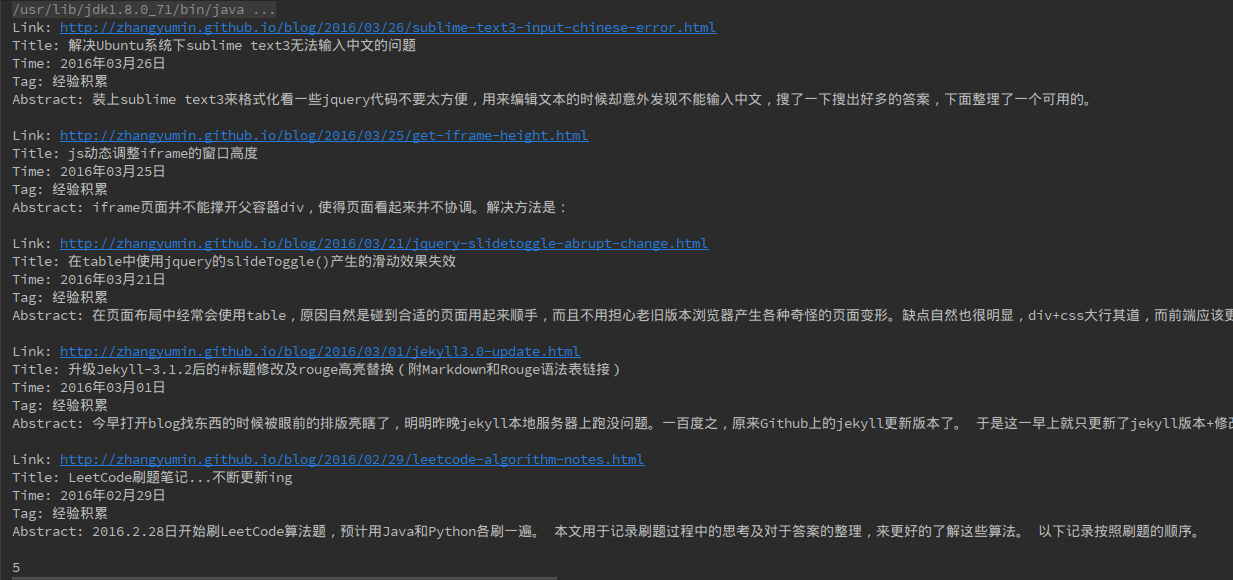
运行结果
代码
import org.jsoup.*;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* //
* // █████▒█ ██ ▄████▄ ██ ▄█▀ ██████╗ ██╗ ██╗ ██████╗
* // ▓██ ▒ ██ ▓██▒▒██▀ ▀█ ██▄█▒ ██╔══██╗██║ ██║██╔════╝
* // ▒████ ░▓██ ▒██░▒▓█ ▄ ▓███▄░ ██████╔╝██║ ██║██║ ███╗
* // ░▓█▒ ░▓▓█ ░██░▒▓▓▄ ▄██▒▓██ █▄ ██╔══██╗██║ ██║██║ ██║
* // ░▒█░ ▒▒█████▓ ▒ ▓███▀ ░▒██▒ █▄ ██████╔╝╚██████╔╝╚██████╔╝
* // ▒ ░ ░▒▓▒ ▒ ▒ ░ ░▒ ▒ ░▒ ▒▒ ▓▒ ╚═════╝ ╚═════╝ ╚═════╝
* Created by joker on 16-4-2.
*/
public class FirstCrawler {
public static void main(String[] args) throws IOException {
String url = "http://zhangyumin.github.io/";
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/30.0")
.get();
Elements elements = doc.select(".main .post");
for(Element ele : elements){
Elements elementTitle = ele.select(".post-title a");
String title = elementTitle.text();
String link = elementTitle.attr("href").trim();
Elements elementSubTitle = ele.select(".post-meta");
String time = ele.select(".post-meta").first().ownText();
String tag = elementSubTitle.select("a").text();
Elements elementSummary = ele.select(".post-main p");
String summary = elementSummary.text();
System.out.println("Link: http://zhangyumin.github.io" + link);
System.out.println("Title: " + title);
System.out.println("Time: " + time);
System.out.println("Tag: " + tag);
System.out.println("Abstract: " + summary);
System.out.println();
}
System.out.println(elements.size());
}
}