基于webmagic的煎蛋网段子爬虫
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。作者曾经在前公司进行过一年的垂直爬虫的开发,webmagic就是为了解决爬虫开发的一些重复劳动而产生的框架。
用了一两天时间研究了下使用方式和代码,抓煎蛋网的段子页面走了不少的弯路,同样也学会了很多不同方面的知识,比如xpath,regex,jdbc等等,经过不断的调试,终于还是几乎爬下了所有的文本,然后持久化到mysql中去了(有几条由于编码问题没法持久化到mysql)。
准备阶段
1.直接去webmagic官网下载到webmagic-core-0.5.2.jar和webmagic-extension-0.5.2.jar包导入到项目中即可,在maven中也能直接搜索的到。
2.下载jdbc并且导入到项目中去,我们是要把爬到的数据导入到数据库中的。
3.与所有的爬虫一样,先得去网站定位好需要抓取的位置,webmagic支持xpath,regex,css选择器等等,数据筛选起来相对jsoup更加方便。
PageProcesser:
package jandanCrawler;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.model.OOSpider;
import us.codecraft.webmagic.model.annotation.ExtractBy;
import us.codecraft.webmagic.model.annotation.TargetUrl;
import us.codecraft.webmagic.scheduler.FileCacheQueueScheduler;
import us.codecraft.webmagic.scheduler.component.HashSetDuplicateRemover;
import java.util.List;
/**
* //
* // █████▒█ ██ ▄████▄ ██ ▄█▀ ██████╗ ██╗ ██╗ ██████╗
* // ▓██ ▒ ██ ▓██▒▒██▀ ▀█ ██▄█▒ ██╔══██╗██║ ██║██╔════╝
* // ▒████ ░▓██ ▒██░▒▓█ ▄ ▓███▄░ ██████╔╝██║ ██║██║ ███╗
* // ░▓█▒ ░▓▓█ ░██░▒▓▓▄ ▄██▒▓██ █▄ ██╔══██╗██║ ██║██║ ██║
* // ░▒█░ ▒▒█████▓ ▒ ▓███▀ ░▒██▒ █▄ ██████╔╝╚██████╔╝╚██████╔╝
* // ▒ ░ ░▒▓▒ ▒ ▒ ░ ░▒ ▒ ░▒ ▒▒ ▓▒ ╚═════╝ ╚═════╝ ╚═════╝
* Created by zym on 16-4-10.
*/
//TargetUrl是从页面上继续发现待爬取页面的网址,并加入到待爬取list中去
@TargetUrl("http://jandan.net/duan/page*")
//从页面重复按块重复抓取数据,用multi = true来标记
@ExtractBy(value = "//div[@class='row']", multi = true)
public class JandanPageProcesserAnno {
@ExtractBy(value = "//div[@class='text']/p/text()")
private List<String> text;
@ExtractBy(value = "//span[@class='righttext']/a/text()")
private String id;
//xpath和regex的结合,用来过滤掉一些干扰数据
@ExtractBy(value = "//div[@class='vote']/span/text()/regex('>\\d+<')")
private List<String> support;
@ExtractBy(value = "//span[@class='righttext']/regex('page-\\d+')")
private String page;
public static void main(String[] args) {
//setSleepTime来设置抓取间隔,JandanPipelineAnno()是自己实现的抓取后输出管道,setScheduler来加载需要的url管理组件,对已抓取的url进行去重
OOSpider.create(Site.me().setSleepTime(1000), new JandanPipelineAnno(), JandanPageProcesserAnno.class)
.setScheduler(new FileCacheQueueScheduler("/home/workstation/data/crawler/jandan").setDuplicateRemover(new HashSetDuplicateRemover()))
.addUrl("http://jandan.net/duan/page-1")
.thread(5)
.run();
}
}Pipeline:
package jandanCrawler;
import org.apache.commons.lang.builder.ToStringBuilder;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.PageModelPipeline;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
/**
* //
* // █████▒█ ██ ▄████▄ ██ ▄█▀ ██████╗ ██╗ ██╗ ██████╗
* // ▓██ ▒ ██ ▓██▒▒██▀ ▀█ ██▄█▒ ██╔══██╗██║ ██║██╔════╝
* // ▒████ ░▓██ ▒██░▒▓█ ▄ ▓███▄░ ██████╔╝██║ ██║██║ ███╗
* // ░▓█▒ ░▓▓█ ░██░▒▓▓▄ ▄██▒▓██ █▄ ██╔══██╗██║ ██║██║ ██║
* // ░▒█░ ▒▒█████▓ ▒ ▓███▀ ░▒██▒ █▄ ██████╔╝╚██████╔╝╚██████╔╝
* // ▒ ░ ░▒▓▒ ▒ ▒ ░ ░▒ ▒ ░▒ ▒▒ ▓▒ ╚═════╝ ╚═════╝ ╚═════╝
* Created by zym on 16-4-10.
*/
public class JandanPipelineAnno implements PageModelPipeline {
@Override
public void process(Object o, Task task) {
String result = ToStringBuilder.reflectionToString(o);
String text = result.substring(result.indexOf("text=[") + 6, result.indexOf("],id"));
String id = result.substring(result.indexOf("id=") + 3, result.indexOf(",support"));
String support = result.substring(result.indexOf("[>") + 2, result.indexOf("<, >"));
String unsupport = result.substring(result.indexOf("<, >") + 4, result.indexOf("<],"));
String page = result.substring(result.indexOf("page-") + 5, result.lastIndexOf("]"));
try {
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/crawler?useUnicode=true&characterEncoding=GBK", "name", "passwd");
Statement stmt = conn.createStatement();
StringBuffer sql = new StringBuffer("insert into jandan values (" + id + ",'" + text + "'," + support + "," + unsupport + "," + page + ");");
System.out.println(page + ":" + id);
conn.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}结果截图
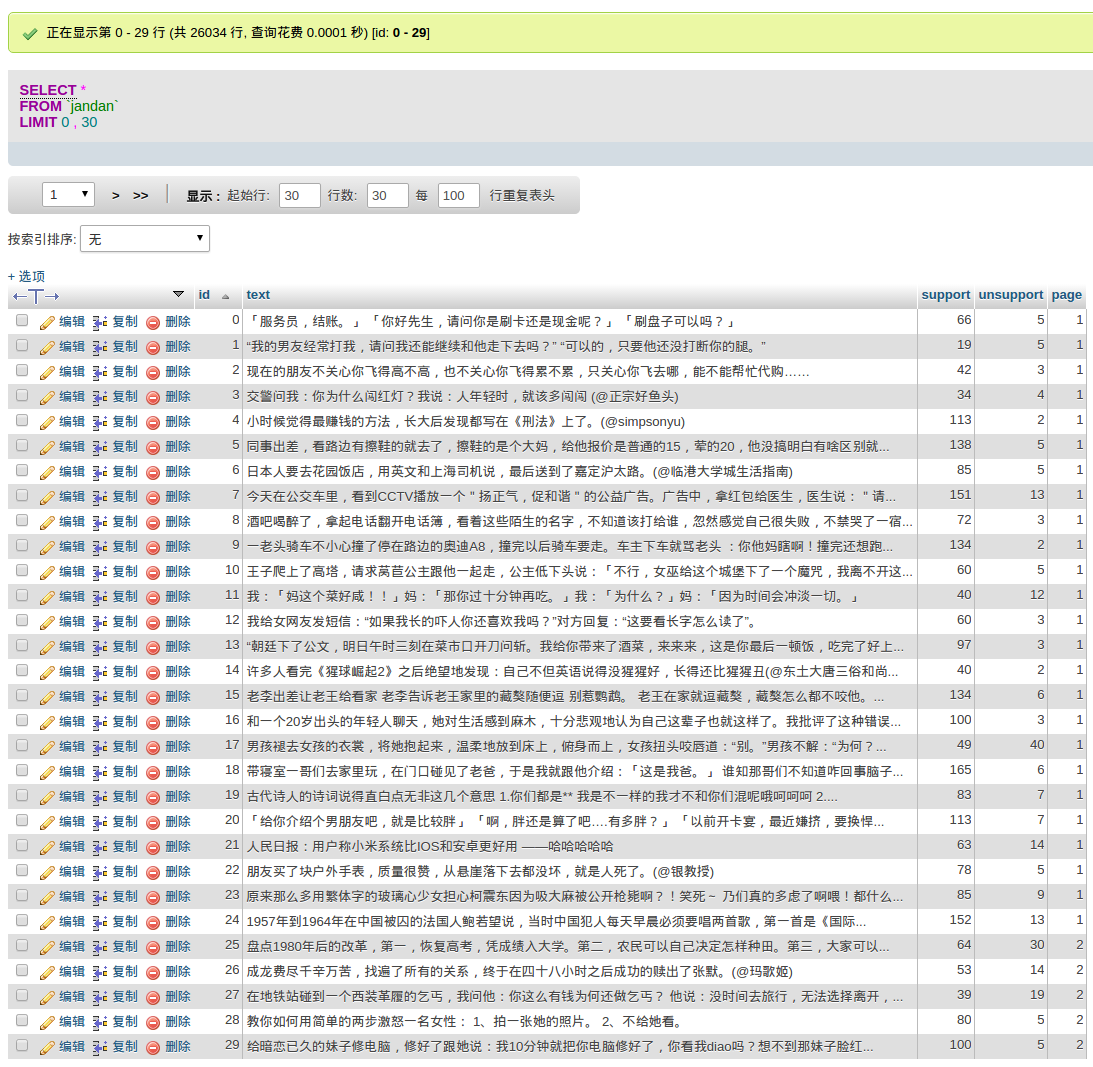
实话说这个爬虫也就仅仅满足了能用的标准,还是一个极低的标准,存在着一大堆的问题。比如并没有很好的去除抓取的数据中的干扰信息,比如重复的开启关闭数据库链接等。大概是写过的Java代码实在是少,一直局限在自己对编程的理解上没什么进步,按照自己的想法写一些丑陋的代码。后边会找很多的机会多写一些,体会OO的精髓,争取早日步入正轨吧。